Research
My research interests lie in the areas of machine learning and computer vision, including graphical models, efficient Markov chain Monte Carlo methods and variational inference methods for Bayesian models, deep learning and reinforcement learning.
My Ph.D. thesis is about a deterministic sampling algorithm known as herding. Herding takes as input a probabilistic distribution or a set of random samples, and outputs pseudo-samples without explicitly specifying a probabilistic model. These pseudo-samples are highly negatively correlated, and convey more information of the input distribution than i.i.d. samples of the same size. I have also worked on Bayesian inference for Markov random fields, as well as efficient and scalable MCMC methods.
At Cambridge, I worked with Prof. Zoubin Ghahramani on scalable inference methods for Bayesian nonparametric models. My long-term interest on this topic is to make Bayesian inference algorithms for (nonparametric) probabilistic models as scalable and easy to use as optimization-based algorithms. A few approaches I have been studying include:
- General scalable approximate MCMC methods for large-scale Bayesian inference, an analogy to stochastic gradient descent in the optimization field.
- Distributed sampling algorithm for Bayesian nonparametric clustering and topic modelling.
- Hybrid inference algorithms that combine stochastic variational inference with MCMC to provide an efficient and accurate posterior distribution. Applications include Gaussian process dynamical systems and nonlinear latent variable models for unsupervised learning.
At DeepMind, I am doing research across multiple machine learning areas including generative models, meta-learning, reinforcement learning, Bayesian inference and causal inference. These works have been applied to Game playing, speech synthesis, image and video generation and robotics.


I feel very privileged to have taken part in the AlphaGo project at DeepMind and helped build an AI program for game Go. AlphaGo beat the world champion, Lee Sedol, in 4 out of 5 games in 2016, defeated 60 top professionals online and world’s number one player, Ke Jie, in 3 out of 3 games in 2017.
The DeepMind AlphaGo team received Inaugural IJCAI Marvin Minsky Medal for Outstanding Achievements in AI in 2017.
We also developed a new version AlphaGo Zero that was trained from scratch without human knowledge and surpassed all the previous versions of AlphaGo after 21 days of training.
AlphaGo Zero is published in Nature in Oct 2017.
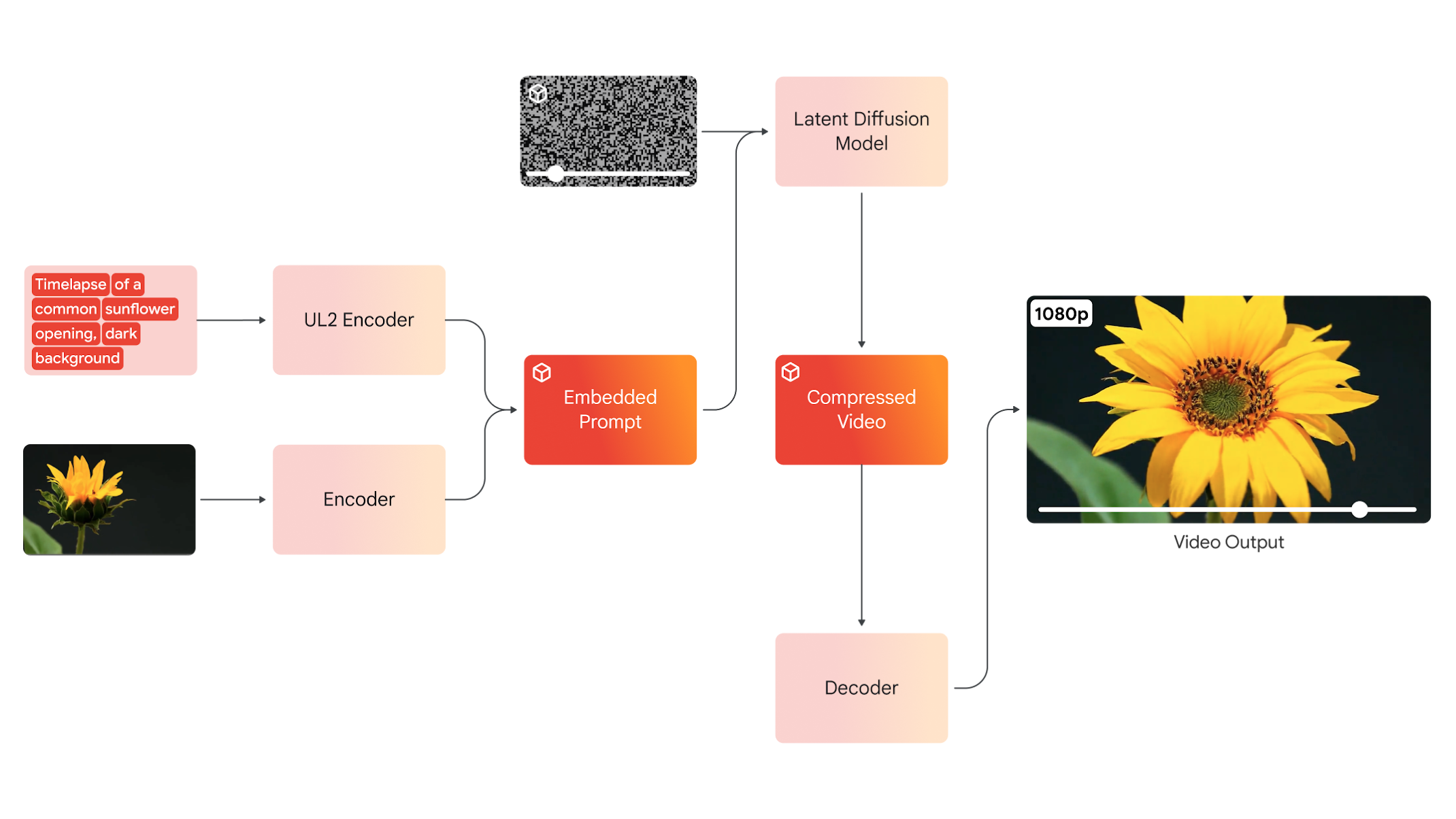
Veo ("to see" in Spanish) is Google's most capable generative video model as of 2024.
It generates high-quality, 1080p resolution videos that can go beyond a minute, in a wide range of cinematic and visual styles. The generated videos closely follow the prompt and maintain visual consistency. It also supports image to video generation.
I lead the development of decoding and super-resolution models.
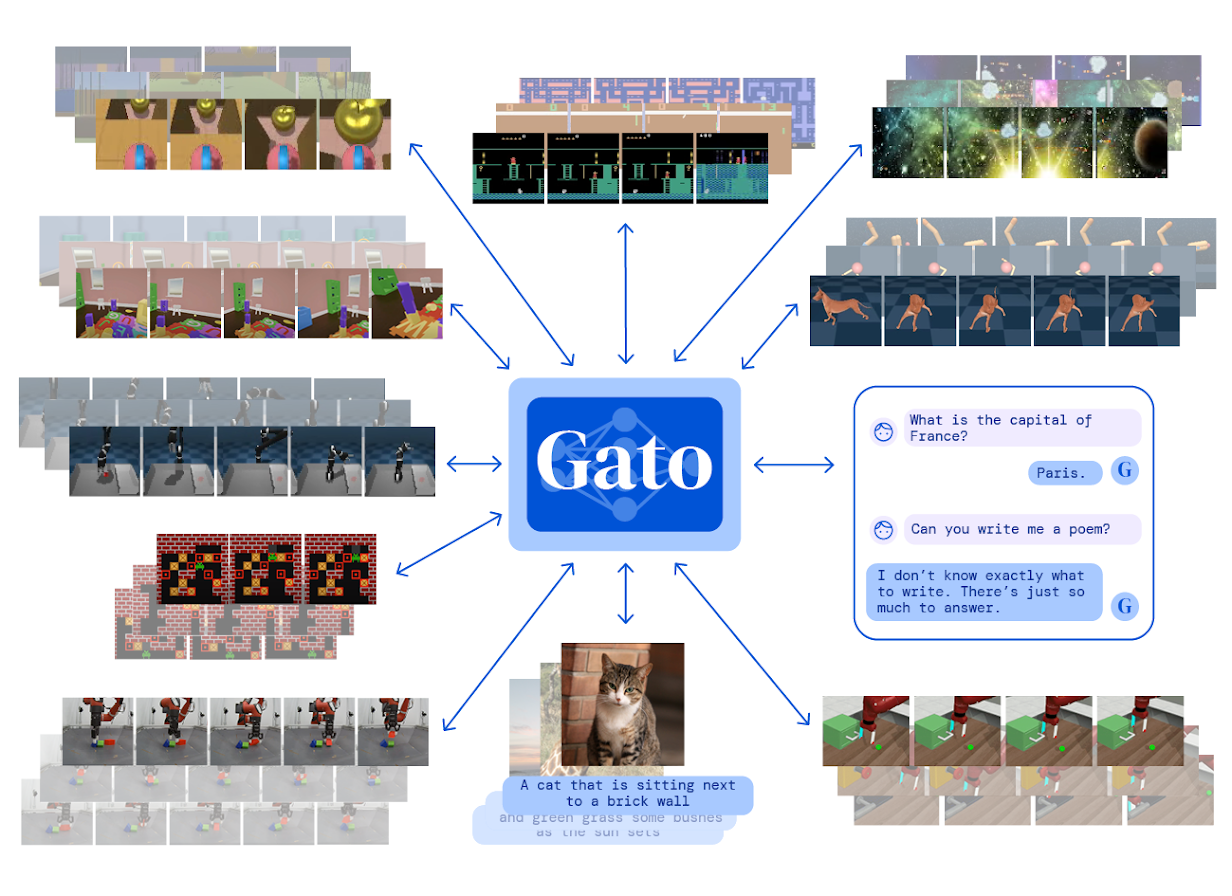
Gato is the first multi-modal, multi-task, multi-embodiment generalist agent that can do dialogue, visual question answering, video gaming and robotics control.
The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.
It was awarded the TMLR Outstanding Paper in 2022, equivalent to a best paper award at a top-tier conference.
Meta-learning for Optimization and OptFormer

I have been passionate in developing better zeroth-order optimization algorithms with meta-learning over years for applications in hyperparameter optimization, experimental design, and robotics evaluation.
I published one of the earliest meta-learnig papers for black-box optimization in 2017, L2L w/o GD by GD,
We also proposed the first foundation models for hyperparameter optimization in 2022, OptFormer, which takes advantage of Google's massive dataset of hyperparameter tuning experiments and is competitive with the GP-based Bayesian optimization algorithm used in production. Check the Google Scholar page for more works along this line of research
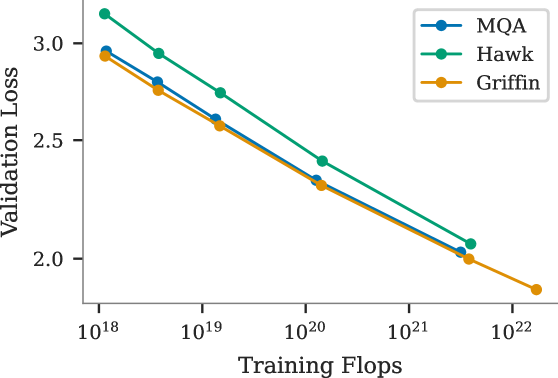
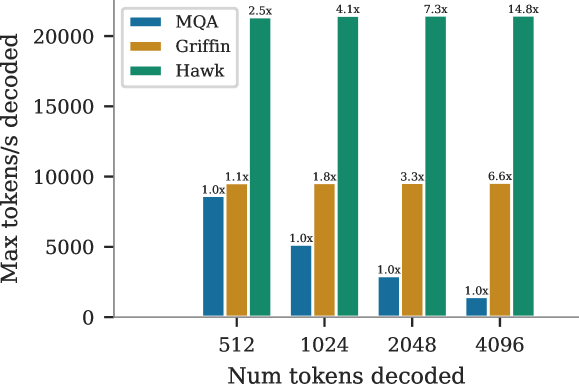
We scaled up a linear recurrent model to 14B parameters. It matches the Gemini performance at the same scale and achieves a much higher inference speed.
This is Google's internal variant of the State Space Model, an alternative to the transformer architecture, and concurrent work of the external Mamba model.
We proposed two variants: Hawk, a pure linear recurrent model, and Griffin, a hybrid and the most performing model. They have been open-sourced as RecurrentGemma.
Voice imitation and video dubbing
I lead the project to synthesized high-fidelity voices with minimal recorded speech data through the method, Sample Efficient Adaptive Text-to-Speech.
We collaborated with Google Project Euphonia and empowered speech-impaired ALS patients for the first time to communicate in their original voice. Reported in the YouTube documentary series "The Age of A.I.". The same idea is also applied to power Google's custom voice service.
We also developed video dubbing technology to automatically translate and dub videos into multiple languages at scale, saving expensive human dubbing cost.
Our model kept the original speaker's voice in the dubbed video and synced their lip movement so that foreign language audiences received the same watching experience as native speakers.